Explicación de la Etapa de Pre-entrenamiento en LLMs
Descubre cómo se desarrolla la etapa de pre-entrenamiento en modelos lingüísticos grandes (LLMs) y su importancia en la inteligencia artificial.
Claves para entender el pre-entrenamiento de LLMs
La etapa de pre-entrenamiento es la fase fundamental en el desarrollo de modelos lingüísticos grandes (LLMs, por sus siglas en inglés, Large Language Models) como ChatGPT, Gemini, Claude, etc.
Este proceso implica exponer el modelo a enormes cantidades de datos de texto diversos para permitirle aprender patrones lingüísticos generalizados, estructuras y semántica. A continuación, se presenta una exploración detallada de esta etapa crítica, incluyendo sus objetivos, metodologías, desafíos e impacto.
Objetivos del Pre-entrenamiento
El pre-entrenamiento tiene como objetivo crear un modelo base versátil y escalable capaz de comprender y generar lenguaje en diversos contextos. A diferencia del fine-tuning (ajuste fino), que se enfoca en ajustes específicos para tareas, el pre-entrenamiento establece una amplia base lingüística.
- Conocimiento Lingüístico Generalizado: El pre-entrenamiento dota a los LLMs de la capacidad de procesar diversas estructuras lingüísticas en diferentes dominios.
- Base para el Fine-Tuning: La fase de pre-entrenamiento construye un marco robusto que luego puede ser ajustado para aplicaciones especializadas.
- Comprensión de Relaciones Complejas: Al analizar grandes datasets, los LLMs aprenden relaciones sintácticas y semánticas dentro del texto.
Recolección de Datos para el Pre-entrenamiento
Fuentes de Datos
- Datos Generales: Páginas web, libros, conversaciones y publicaciones de redes sociales.
- Datos Especializados: Artículos científicos, código de programación o corpus multilingües.
Volumen de Datos
La escala de los datos de pre-entrenamiento es crucial. Por ejemplo, GPT-3 fue entrenado con aproximadamente 570GB de datos de texto, mientras que datasets modernos como Pile Web contienen billones de tokens.

Preprocesamiento de Datos
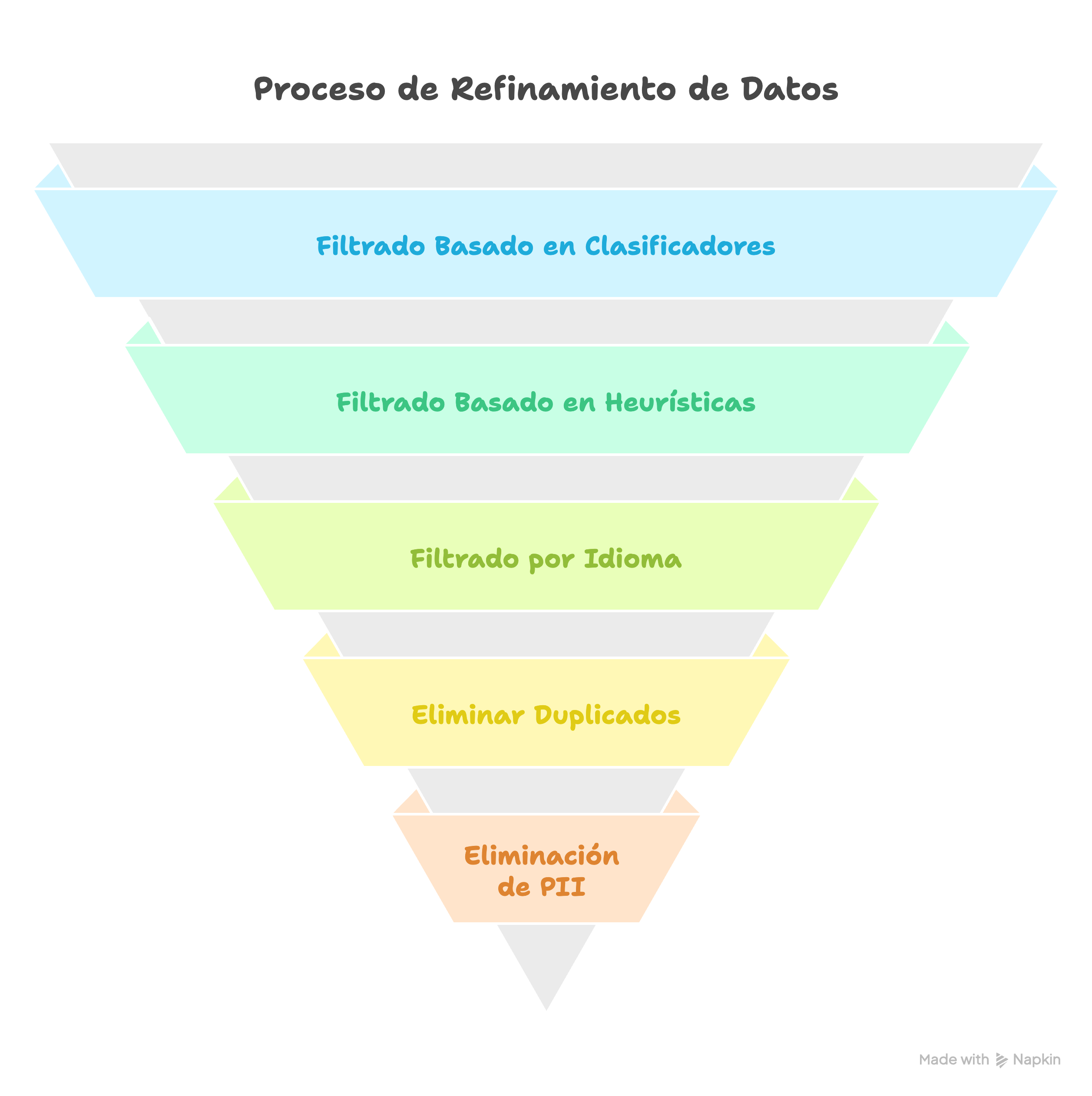
- Filtrado Basado en Clasificadores (Classifier-Based Filtering): Un classifier (clasificador) binario identifica textos de alta calidad (por ejemplo, páginas de Wikipedia) mientras filtra datos de baja calidad. Sin embargo, este método corre el riesgo de excluir contenido valioso en lenguajes dialectales o coloquiales
- Filtrado Basado en Heurísticas (Heuristic-Based Filtering): Son métodos basados en reglas (heuristics) que eliminan contenido ruidoso o irrelevante usando técnicas como el filtrado por idioma (por ejemplo, eliminar textos que no estén en inglés), filtrado basado en métricas (por ejemplo, puntuaciones de complejidad) y filtrado basado en palabras clave (por ejemplo, eliminar tags HTML).
- Filtrado por Idioma: Los clasificadores de idioma determinan el idioma dominante en cada documento. Por ejemplo:
- Modelos enfocados en inglés pueden excluir textos que no estén en inglés.
- Los modelos multilingües retienen datos lingüísticos diversos para mejorar el rendimiento interlingüístico.
- Eliminar duplicados (Deduping): Se eliminan las entradas duplicadas para prevenir la redundancia en los datos de entrenamiento. El contenido duplicado puede perjudicar el rendimiento del modelo al saturar los procesos de entrenamiento o reducir la capacidad de generalización.
- Eliminación de información personal (PII): La Información de Identificación Personal (PII, por sus siglas en inglés, Personally Identifiable Information), como direcciones o números de Seguridad Social, se filtra para asegurar un uso ético de los datos.
Técnicas Utilizadas en el Pre-entrenamiento
El pre-entrenamiento emplea técnicas de aprendizaje no supervisado o auto-supervisado que permiten a los modelos aprender patrones sin etiquetas explícitas. Los métodos comunes incluyen:
- Modelado de Lenguaje Enmascarado (MLM, Masked Language Modeling)
- Se ocultan tokens dentro de las secuencias, y el modelo predice los elementos enmascarados.
- Esta técnica ayuda a los modelos a comprender la semántica a nivel de palabra y las estructuras de las oraciones.
- Predicción de la Siguiente Oración (NSP, Next Sentence Prediction):
- El modelo predice si dos oraciones son consecutivas.
- NSP mejora la comprensión del discurso y el flujo contextual.
- Modelado de Lenguaje Causal (CLM, Causal Language Modeling):
- CLM entrena a los modelos para predecir el siguiente token en una secuencia basándose en los tokens anteriores..
- Esta técnica sustenta modelos autorregresivos como GPT y es esencial para tareas de generación de texto.
Desafíos en el Pre-entrenamiento
- Intensidad de Recursos. El pre-entrenamiento requiere recursos computacionales significativos:
- El proceso requiere grandes cantidades de poder computacional.
- El pre-entrenamiento puede requerir más memoria y tiempo de procesamiento que el ajuste fino.
- Disponibilidad de Datos: Obtener datos diversos de alta calidad puede ser difícil.
- Las aplicaciones multilingües o especializadas a menudo requieren datasets curados que pueden no ser fácilmente accesibles
- Equilibrio Generalización vs Especialización: Los modelos deben aprender patrones generalizados sin ajustarse excesivamente a datasets específicos:
- Un enfoque excesivo en un dominio puede obstaculizar el rendimiento en otras áreas.
- Los investigadores equilibran cuidadosamente las proporciones de datos de diferentes fuentes durante el pre-entrenamiento.
Impacto del Pre-entrenamiento
La etapa de pre-entrenamiento influye profundamente en las capabilities de un LLM:
- Versatilidad Base:
- Los modelos pre-entrenados pueden manejar una amplia gama de tareas antes del fine-tuning.
- Por ejemplo, los modelos GPT se utilizan para aplicaciones que van desde la escritura creativa hasta bots de soporte al cliente.
- Mejora del Rendimiento en Tareas Posteriores (Downstream Tasks):
- Los modelos entrenados con datos filtrados de alta calidad rinden mejor en tareas downstream (posteriores en el flujo de trabajo) como el análisis de sentimiento o la respuesta a preguntas
- Estudios muestran que limpiar los datasets de entrenamiento mejora la estabilidad y la capacidad de generalización durante el entrenamiento.
- Escalabilidad:
- Datasets más grandes combinados con arquitecturas avanzadas permiten escalar los parámetros del modelo sin comprometer la eficiencia.
- Por ejemplo, GPT-4 incorpora billones de parámetros manteniendo un alto rendimiento en diversas tareas
Conclusión
La etapa de pre-entrenamiento es crítica para el éxito de los modelos lingüísticos grandes. Aunque implica desafíos importantes, sus beneficios en términos de versatilidad, escalabilidad y rendimiento en tareas específicas lo convierten en un proceso esencial para el desarrollo de sistemas de IA avanzados.
Estas son algunas de las fuentes y articulos que podrían ayudarte a profundizar en el tema: