Etapa de Post-entrenamiento en LLMs
Despues de pre-entrenar el modelo con grandes cantidades de datos, es capaz de generar texto con fluidez estadistica, pero le falta seguridad y habilidades conversacionales. Conoce cómo se refina en la etapa de post-entrenamiento.
Entendiendo la Etapa de Postentrenamiento en Modelos de Lenguaje de Gran Escala (LLMs)
Después de preentrenar un modelo de lenguaje con grandes cantidades de datos de internet, el modelo resultante es capaz de generar texto con fluidez estadística, pero carece de dirección, seguridad y habilidades conversacionales. Para refinarlo y hacerlo útil en aplicaciones reales, se lleva a cabo una fase crítica llamada postentrenamiento, que incluye el ajuste fino supervisado (SFT) y el aprendizaje por refuerzo con retroalimentación humana (RLHF).
¿Qué es el postentrenamiento?
El postentrenamiento ocurre después del preentrenamiento pero antes de poner el modelo a disposición del público. Mientras que el preentrenamiento desarrolla un conocimiento general del lenguaje, el postentrenamiento adapta ese conocimiento a tareas específicas como seguridad, utilidad y coherencia conversacional. Es esencial para transformar un modelo genérico en un asistente confiable.
1. Ajuste Fino Supervisado (SFT)
En esta etapa:
- Se crea un conjunto de datos curado con conversaciones.
- Etiquetadores humanos escriben prompts y respuestas ideales.
- El modelo base se ajusta para imitar ese comportamiento.
Aunque se parece al preentrenamiento en términos algorítmicos, lo importante es el tipo de datos: ahora el modelo aprende de conversaciones humanas, no de texto no estructurado. Esto le permite comportarse como un asistente, negarse cortésmente a solicitudes indebidas y desarrollar un tono adecuado.
2. Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF)
RLHF es la etapa final del postentrenamiento. Introduce bucles de retroalimentación basados en preferencias humanas mediante un modelo de recompensa.
El proceso es el siguiente:
- Etiquetadores humanos ven múltiples respuestas del modelo.
- En lugar de escribir la respuesta ideal, las ordenan de mejor a peor.
- Esas clasificaciones entrenan un modelo de recompensa que simula el juicio humano.
- El modelo principal se ajusta mediante aprendizaje por refuerzo para maximizar esa recompensa.
Esto permite mejorar incluso en tareas subjetivas como contar chistes o escribir poemas, donde no hay una respuesta correcta única.
¿Por qué importa el postentrenamiento?
- Alineación con valores humanos: seguridad, tono, ética.
- Mejor calidad de respuestas: más útiles y coherentes.
- Mejor seguimiento de instrucciones.
- Reducción de alucinaciones y contenido dañino.
Por ejemplo, los modelos preentrenados tienden a inventar hechos (alucinaciones). El postentrenamiento ayuda a mitigarlo e incluso permite integrar herramientas externas como navegadores o intérpretes de código para mejorar la precisión.
Comparación con el aprendizaje humano
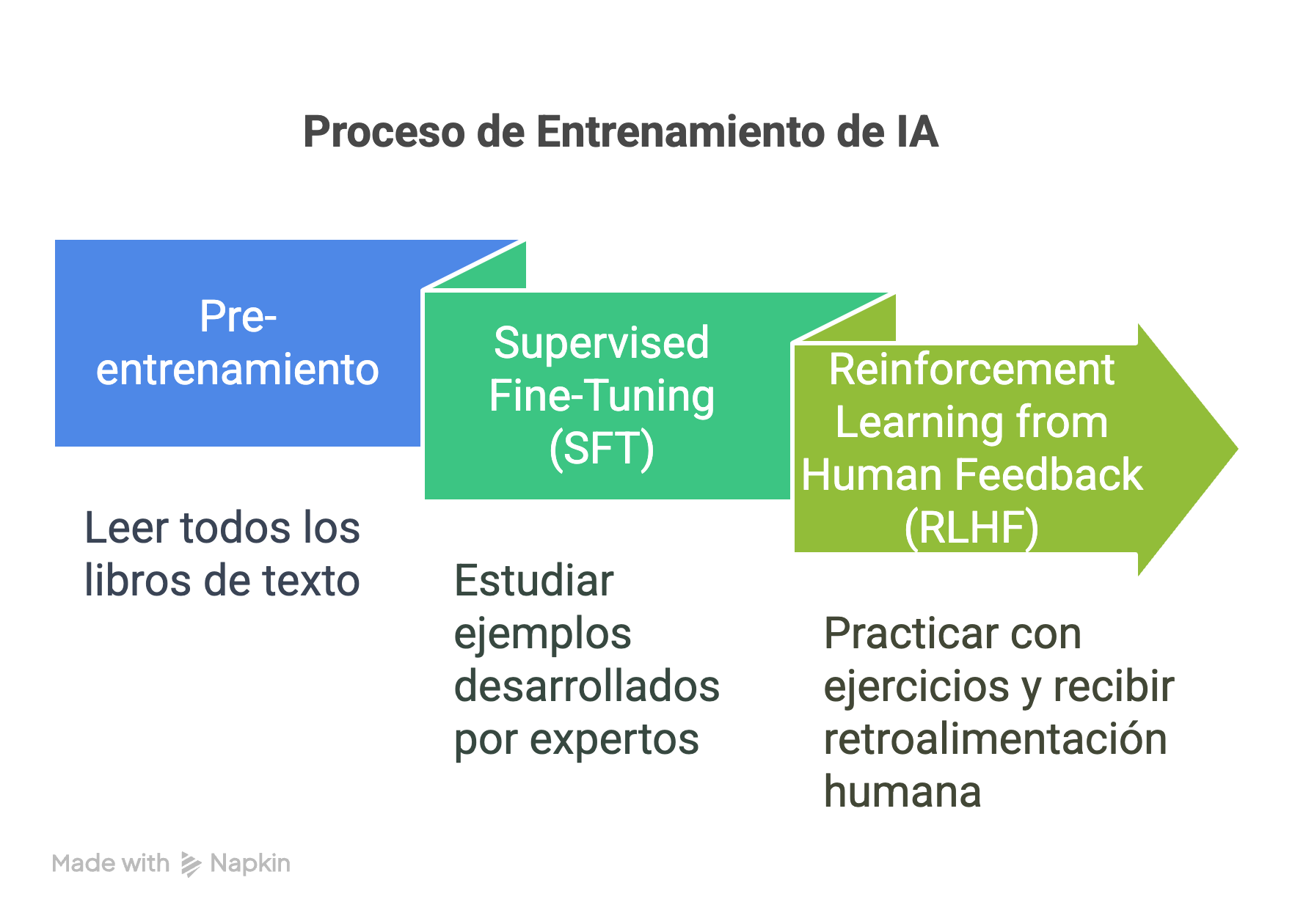
Una analogía útil es comparar el entrenamiento del modelo con la educación humana:
- Preentrenamiento: leer todos los libros de texto.
- SFT: estudiar ejemplos resueltos por expertos.
- RLHF: practicar con ejercicios y recibir retroalimentación.
Desafíos del RLHF
- El modelo de recompensa no es perfecto.
- El modelo puede encontrar formas de manipular ese sistema y obtener buena puntuación sin mejorar la calidad real.
- Puede ocurrir colapso del modo: las respuestas se vuelven repetitivas o poco diversas.
Aun así, es el método más escalable y efectivo que tenemos para afinar modelos a gran escala.
Investigación en curso
RLHF sigue evolucionando. Algunos avances recientes incluyen:
- Mejor entrenamiento del modelo de recompensa.
- Uso de LLMs como jueces para evaluar otras respuestas.
- Optimización del tipo de prompts usados durante la práctica.
A medida que los modelos crecen, también lo hace la complejidad del postentrenamiento. Pero su refinamiento es lo que transforma un modelo inteligente en uno verdaderamente útil y confiable.
Conclusión
Comprender el postentrenamiento es clave para entender cómo un modelo crudo se convierte en un asistente con el que podemos hablar cada día. Aquí es donde se diseñan la seguridad, utilidad y comportamiento del modelo: no con reglas fijas, sino mediante datos curados y aprendizaje iterativo.