¿Qué es la inferencia en LLMs?
Descubre cómo se desarrolla la etapa de pre-entrenamiento en modelos lingüísticos grandes (LLMs) y su importancia en la inteligencia artificial.
Comprendiendo la Inferencia en Modelos de Lenguaje de Gran Escala (LLMs)
La inferencia es un concepto crucial en el ciclo de vida de un modelo de lenguaje grande como ChatGPT. Mientras que el preentrenamiento y el ajuste fino construyen la base de lo que un modelo "sabe" y cómo se comporta, la inferencia es el momento en el que este conocimiento se utiliza para generar respuestas en tiempo real. Este proceso permite que el modelo complete indicaciones, mantenga conversaciones y simule escritura humana basada en los patrones aprendidos durante el entrenamiento.
¿Qué es la inferencia?
La inferencia se refiere a la fase en la que se utiliza un LLM entrenado para generar salidas basadas en una entrada o "prompt" proporcionado por el usuario. A diferencia de la fase de entrenamiento, no hay aprendizaje ni ajuste de parámetros durante la inferencia. El modelo simplemente toma lo que ya ha aprendido y lo aplica a nuevas entradas para generar texto coherente y relevante.
Por ejemplo, cuando escribes en ChatGPT, no estás "entrenando" el modelo, sino que lo estás usando en modo de inferencia. Los parámetros del modelo están fijos y las respuestas se generan en función de predicciones probabilísticas.
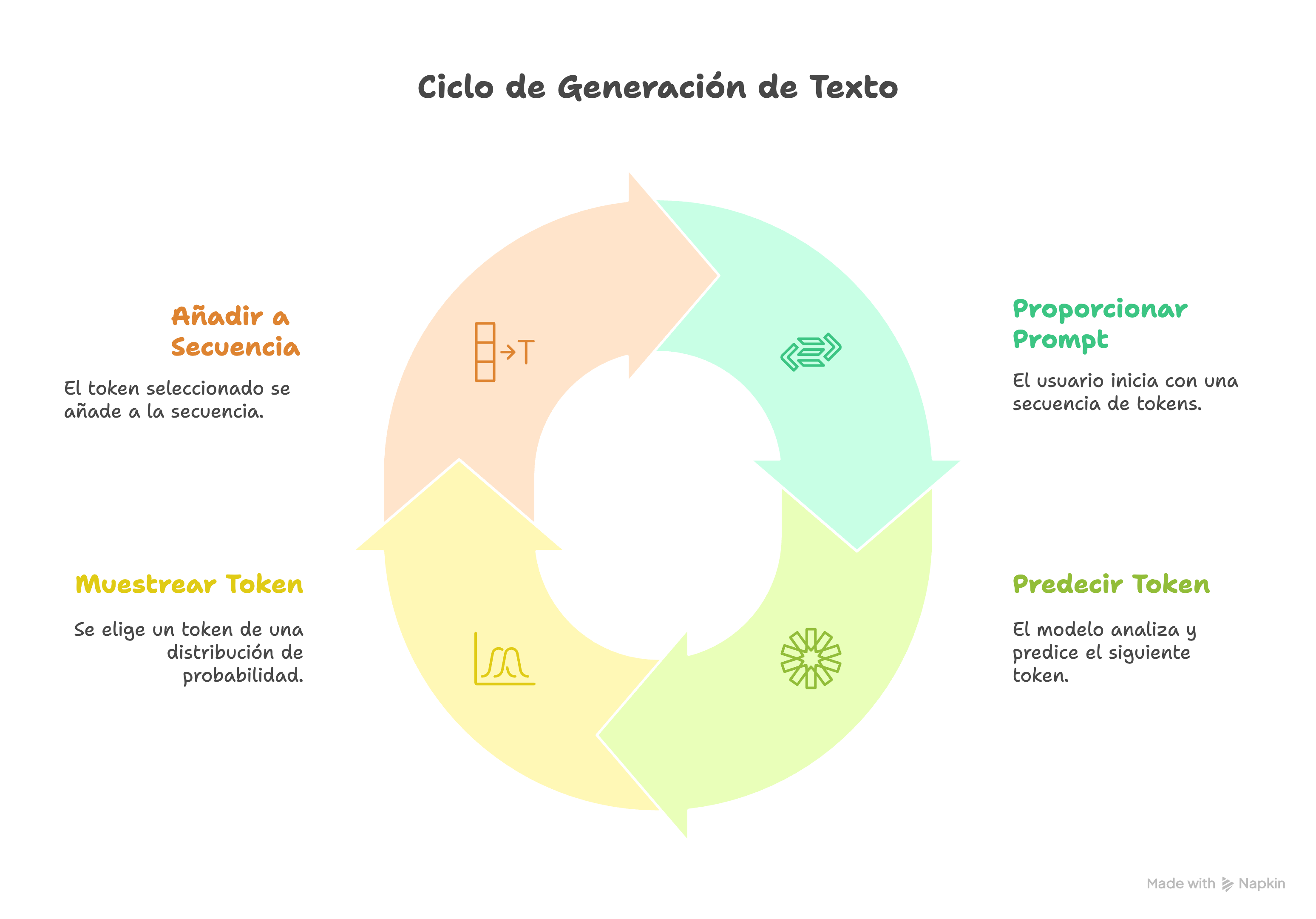
¿Cómo funciona la inferencia?
El proceso de inferencia puede entenderse como un autocompletado sofisticado:
- Comienza con un prompt: el usuario proporciona una secuencia de tokens.
- Predicción del siguiente token: el modelo analiza la secuencia y predice cuál es el siguiente token más probable.
- Muestreo: en lugar de elegir siempre el token más probable, se muestrea desde una distribución de probabilidad para mantener la variedad y naturalidad.
- Repetición: el token generado se añade a la secuencia, y el proceso se repite hasta cumplir con una condición de parada.
Naturaleza estocástica de la inferencia
La inferencia es no determinista, lo que significa que puedes recibir respuestas diferentes a partir del mismo prompt. Esto se debe al proceso de muestreo aleatorio, lo cual permite creatividad, pero también introduce variabilidad.
Inferencia con herramientas externas
Algunos LLMs avanzados, como versiones de ChatGPT con navegación web o ejecución de código, permiten uso de herramientas durante la inferencia:
- El modelo genera tokens especiales para indicar que quiere usar una herramienta (ej. búsqueda web).
- El motor de inferencia pausa la generación al detectar estos tokens.
- Se ejecuta la herramienta y los resultados se insertan en la ventana de contexto como nuevos tokens.
- El modelo retoma la generación con la nueva información en contexto.
¿Dónde encaja la inferencia en el ciclo de vida del modelo?
La inferencia es la fase final en el ciclo de vida de un modelo LLM:
- Preentrenamiento: el modelo aprende lenguaje a gran escala a partir de textos.
- Postentrenamiento o ajuste fino: mejora el comportamiento del modelo en tareas específicas y conversación.
- Inferencia: el modelo se utiliza en producción para responder a nuevos prompts.
Características clave de la inferencia
- Parámetros fijos: los pesos del modelo no cambian.
- Impulsado por el contexto: la calidad del prompt impacta el resultado.
- Generación secuencial: el texto se construye token por token.
- Sin memoria persistente: salvo por la ventana de contexto, el modelo no recuerda interacciones pasadas.
¿Por qué es importante entender la inferencia?
Comprender la inferencia ayuda a:
- Diseñar mejores prompts
- Tener expectativas realistas
- Entender la variabilidad de las respuestas
- Reconocer que el modelo no "sabe", sino que predice lo más probable
En última instancia, la inferencia es el momento en que todo el costoso entrenamiento y desarrollo técnico se convierte en interacción dinámica, generando texto en tiempo real.
Resumen
Entender cómo funciona la inferencia en los LLMs nos permite desmitificar estas herramientas. No estamos hablando con una inteligencia consciente, sino con un motor estadístico de predicción entrenado para simular el lenguaje humano a partir de patrones. Saber esto nos permite aprovechar mejor sus capacidades y también sus limitaciones.